

MedEval
A framework for performance evaluation of AI systems for care delivery

AI systems operating in care delivery must obviously be evaluated for technical accuracy and performance. However, the current crop of scenario-based benchmarks do not approximate real-world conditions and are not sufficient for understanding the performance, failure modes and areas of drift that may occur when an AI system is deployed into production. The refrain that “multiple choice is not real life” is accurate - and more importantly, “static is not dynamic.” We all understand through experience that it is a different experience to do improv than it is to read a script.
Additionally, evaluation criteria need to approximate something that is both understandable and valid as representative performance in a domain and care setting. An extremely talented generalist will struggle in the cardiac ICU, just as a seasoned CT surgeon will be unequipped to manage a complex primary care panel. In medicine, our evaluations accomplish this by structuring assessments first by general medical knowledge (USMLE), then by domain (specialty boards), then by site of care and patient population (CME). With AI, a similar paradigm can be employed.
MedEval is a framework for structuring the evaluation of AI systems in care delivery to assess technical performance and identify failure modes in the system in which they are expected to exist. At its core, it answers two questions:
How often and under what circumstances does AI perform well?
How often and under what circumstances does AI underperform?
MedEval has 5 components which allow for flexible design of evaluations and which map to current professional assessment.
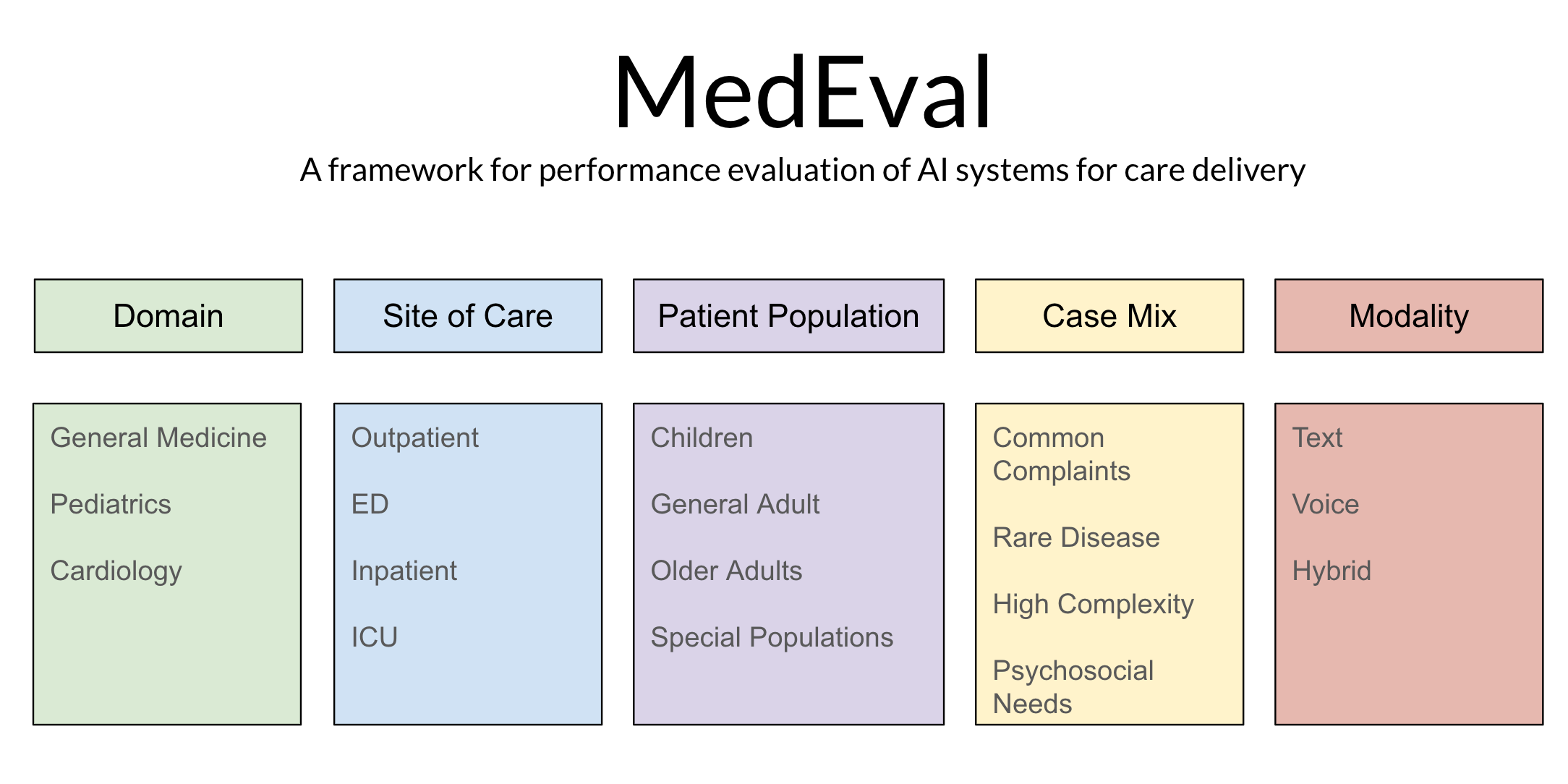
Domain refers to the knowledge base expected to be assessed. This may range from general to highly specialized.
Site of Care then modifies that assessment to include the types of medical conditions which are encountered in different care settings.
Patient Population further tailors the evaluation by varying the types of patients in which these medical conditions manifest in order to capture how disease affects different populations differently.
Case Mix adjusts the acuity, complexity and commonality of examined cases.
Modality adjusts for how an AI is expected to interact with a patient (text, voice or multi-modal).
With this system in place, AI systems can now begin to be evaluated for performance on representative scenarios that start to look a lot more like those they will encounter in the real-world.
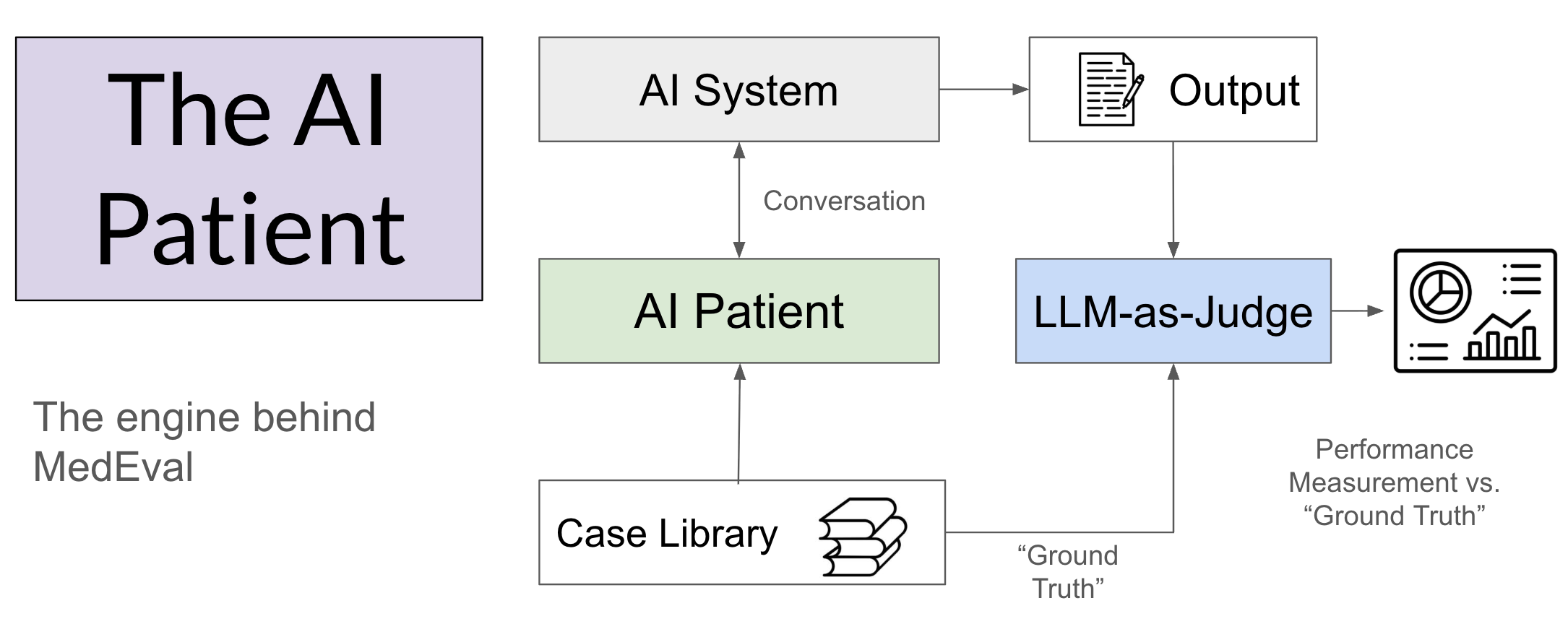
The engine that powers MedEval is the AI Patient. These are synthetic cases that encode a “ground truth” upon which to base the interaction with the AI system being tested. These AI Patients are conceptually the same as the standardized patients encountered by clinical trainees throughout their career. They have a complete backstory and a known diagnosis upon which to base the subsequent evaluation of performance. Because the cases can be reused, performance in individual cases and in aggregate can be examined over time. The evaluation uses an LLM-as-judge to score the case series, with focused human review utilized selectively.
It is tempting to ask how MedEval should be “scored,” but that is not the intent of this piece. There are many valid approaches to measurement. Some will be obvious - like diagnostic accuracy or treatment concordance. But other factors become more nuanced to “measure” per se versus observe - especially complex, cascading failure modes and nuanced situational deviations. Furthermore, measurement schema will also need to introduce many new domains beyond diagnosis and treatment including communication quality, comprehensiveness of the history, ability to surface information, ethical behaviors, readability, empathy, etc.
The more important question is what kind of performance should we expect? But this is not a binary question. AI doesn’t “pass the test” - it just does better or worse. It is not unreasonable to define minimum thresholds and to base them on some heretofore undefined standard, but that also creates opportunity for gamification. To quote Don Wheeler from Understanding Variation: Managing Chaos:
“When people are pressured to meet a target value, there are three ways to proceed:
They can work to improve the system
They can manipulate the system
They can manipulate the data”
MedEval should encourage good faith improvement of the system, not manipulation to hit a target. This is particularly true because AI does not exist in isolation, but within complex systems. An AI with relatively “high” diagnostic concordance may be unsuitable for deployment if diagnostic accuracy is not materially important. Alternatively, an AI with low expected diagnostic concordance might actually represent step change improvement within the current system and merit deployment. These questions are situational and varied, not predictable and routine. And most importantly, technical performance is just one input into the ultimate decision to deploy when using a Care Worthiness standard.
MedEval is a measurement framework for others to build upon, not a prescription for how the evaluation must be carried out. As we migrate from static to dynamic benchmarks, the MedEval framing can be applied to diverse types of AI systems in care delivery, with results tailored directly to the specific usage expected of the technology.
Great framework, Byron. One dimension I’m thinking about that deserves explicit inclusion: appropriate non-use.
MedEval evaluates how well AI performs when consulted, but doesn’t address whether the consultation should have happened at all. In practice, the biggest failure mode may not be a wrong diagnosis but a system that encourages overconsumption of care. Health anxiety scales differently when you give people a frictionless 24/7 medical chatbot.
Should MedEval include metrics for how well a system closes conversations, redirects to real-world care, confidently recommends doing nothing, or reduces its own utilization over time?
Very interesting as always. This stuck out: "other factors become more nuanced to “measure” per se versus observe - especially complex, cascading failure modes and nuanced situational deviations." Interesting to think about how the greatest impact could be a tiny error that cascades to catastrophe.